
Unstructured data refers to information that doesn’t follow a predefined model, like PDFs, images, chats, or emails. It’s flexible but hard to search, categorize, or govern.
Large enterprises have billions of files with data. And that data is often scattered across multi-cloud architectures, with complex ownership and permissions. Across digital files – and sometimes still on paper. That’s what we call unstructured data, and this article is all about unstructured data discovery and how to go about it more efficiently.
Key takeaways
- Unstructured data is everywhere – from PDFs and emails to chat logs and scanned documents – and it’s growing exponentially across every industry.
- Most organizations lack visibility into their unstructured content, making unstructured data discovery essential for data security, compliance, and governance.
- The Collibra + Ohalo Data X-Ray integration gives enterprises a scalable, automated way to discover, classify, and govern unstructured data across multi-cloud and hybrid environments.
- With automated discovery, businesses can reduce compliance risk, accelerate migrations, support AI governance, and turn unstructured data from a liability into an asset.
- Industries like banking, insurance, healthcare, and the public sector benefit the most because they rely on sensitive, high-risk unstructured data.
- The future of unstructured data discovery lies in continuous scanning, AI-driven classification, real-time metadata exchange, and integrated data governance ecosystems.
Understanding unstructured data: what makes it so tricky?
Let’s start with the basics: unstructured data refers to information that doesn’t follow a predefined data model. So while structured data is easy to query and analyze, unstructured data often feels like digging through old boxes in the attic – you know there’s valuable stuff inside, but finding it (and knowing what to do with it) is another story.
Some common examples of unstructured data you’ll recognize immediately include:
- PDFs (lots of PDFs…)
- Emails and attachments
- Scanned documents and screenshots
- Chat logs from Teams, Slack, or customer service chats
- Word and PowerPoint files
- Images and audio recordings
And the amount of data just keeps growing. Every meeting creates notes stored on Google Drive (or even locally), every process generates new documents, and every customer interaction leaves behind digital traces. This enormous amount of data quickly becomes a challenge when you need to know:
- Where the sensitive data is
- Who has access
- Whether the information is still relevant
- How it impacts compliance obligations
- Whether it poses any data security risks
This is where most organizations hit a wall. Unstructured data often ends up scattered across data repositories, making it nearly impossible to track. And without visibility, you can’t protect it.
Why unstructured data discovery matters more than ever
If you’re going to protect your data, comply with regulations, and build trust internally, you need to actually know what data you have. That’s the role of the data discovery process – to reveal what’s hidden across all your data sources, classify it, and bring it into the light.
With unstructured information, the data discovery process is really essential.
And that’s because:
- Sensitive information often hides in unexpected places
- Files can sit forgotten for years, becoming dark data
- Duplicate documents multiply like gremlins (Plus all the edited versions with file names growing by the minute.)
- Personal data slips into email threads
- Outdated or unnecessary content creates risk
So sensitive data discovery is crucial, especially when you consider regulations like the GDPR (but also, many more). If you don’t know what’s in your files, you can’t safeguard it or enforce data retention rules. You also can’t evaluate the risks associated with data or maintain strong data security and compliance practices.
And this leads us directly to the challenge: manually searching through unstructured data sources is impossible at scale. You need automated tools – preferably ones powered by machine learning – to uncover sensitive data within unstructured data without slowing down the organization (or hiring entire teams just to do that).
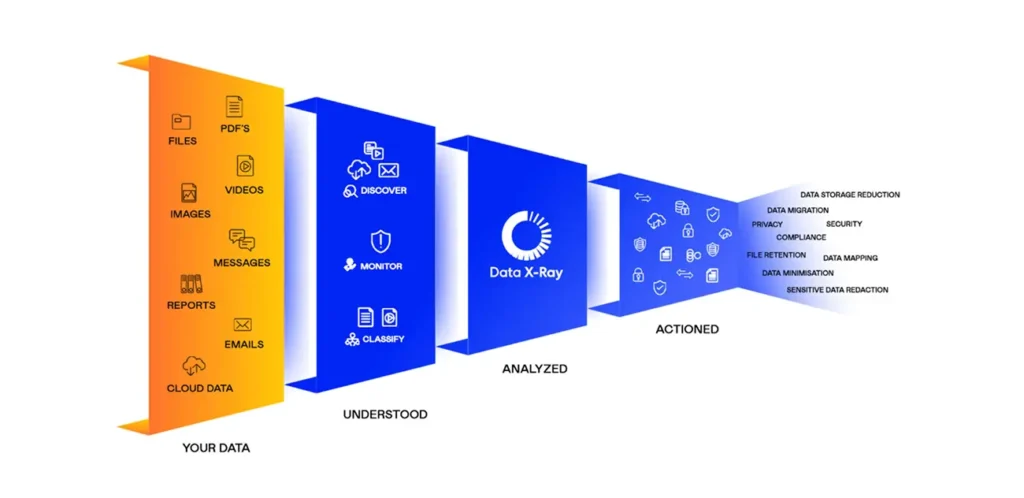
Collibra + Ohalo Data X-Ray: a powerful combination for unstructured data discovery
Now for the good part: how organizations can actually tackle all of this.
The integration between Ohalo Data X-Ray and Collibra creates a robust ecosystem for unstructured data discovery. And having implemented it ourselves at Murdio, we’ve seen how much clarity and control it gives enterprises. Plus, how much time it saves in the process.
What Ohalo Data X-Ray brings to the table
Ohalo Data X-Ray uses automation and machine learning to scan everything from shared drives to document repositories. By combining OCR technology with AI, it can:
- Identify different data types
- Locate sensitive information (even when hidden inside long PDFs)
- Tag and classify files
- Automatically find dark data
- Map relationships within the data
- Deliver insight into the amount of data stored across systems
It’s literally like giving your organization X-ray vision into its unstructured world. (The name really is spot on.)
This is especially helpful in sectors like banking, where unstructured data sources hold customer forms, loan applications, ID scans, communication logs, and regulatory documents. With so much regulated personal data, banks need fast, accurate discovery to avoid fines and reduce the risk of data breaches.
What Collibra adds on top
Collibra provides the data governance layer – turning scans and classifications into a searchable, governable data catalog. When Ohalo feeds results into Collibra, organizations get:
- Full visibility into their unstructured landscape
- Clear classification rules and data lineage
- Stronger data governance practices
- Collibra workflows for approvals, stewardship, and remediation
- Better reporting and oversight
- More effective data management across teams
The combined workflow helps companies streamline data, improve data privacy, and build a foundation for long-term, uniform data management across both structured and unstructured environments.
What this looks like in the real world: Murdio’s implementation story
In our recent client project, an international enterprise needed to get control of scattered repositories holding years of unstructured content.
Using Data X-Ray + Collibra, we helped them:
- Understand unstructured data across the organization
- Identify sensitive information within unstructured data
- Classify data based on sensitivity and business purpose
- Build automated workflows for governing the data
- Gain visibility into data within unstructured data sources
- Improve compliance and reduce risk
- Bring disconnected repositories into a complete data landscape
The biggest impact? The organization finally knew what it had, where it lived, and what needed attention. And once everything was classified and cataloged, they could make smart decisions about data retention, ownership, and access.
This is exactly the moment when unstructured data goes from being a liability to becoming an asset for the company.
Read more in this case study: Discovering, classifying and cataloging unstructured data for a European bank
Industry use cases: where unstructured data discovery really shines
The most prominent use cases for unstructured data discovery using Ohalo Data X-Ray + Collibra include:
- Regulatory compliance and records/file retention (redundant, obsolete, and trivial data lifecycle)
- Data migration governance (M&A data carve-outs and carve-ins and cloud/on-prem systems migrations)
- AI Governance, with curation of ingested data and cleaning sensitive data.
Of course, these can pertain to any industry, but there are some that could particularly benefit from automating unstructured data discovery:
Banking
Banks handle a massive volume of unstructured data every day. Unstructured data discovery tools help identify personal data scattered across repositories, enforce data protection, and reduce compliance risk.
Insurance
Claims photos, reports, policy documents – it can get chaotic. Unstructured data discovery helps insurers prioritize what matters, classify documents faster, and improve decision-making.
Healthcare
Hospitals generate enormous unstructured datasets – imaging, notes, scanned forms, you name it. Protecting sensitive data here is a critical part of patient care and compliance.
Public sector
Government agencies face the challenge of long-standing archives and legacy systems. Automated discovery brings consistency, oversight, and transparency.
– – –
In all these cases, Ohalo Data X-Ray in tandem with Collibra can automate data governance and ongoing discovery and compliance:
- Speed up the population of the Collibra data catalog across the enterprise data landscape
- Link and maintain physical data assets to the Collibra data catalog
- Exchange, monitor, and update metadata for new sensitive information
- Automate business category mapping to ML-driven personal and sensitive data discovery output, including physical location
How data discovery helps strengthen data governance
A modern discovery process does more than just find data. It helps organizations actually use it. It supports:
- Better insights with effective data classification
- Consistent application of data governance practices
- Stronger data protection and access controls
- The ability to secure unstructured data confidently
- Clear relationships within the data
- Smarter, informed decision-making
When you can classify data based on business relevance, sensitivity, and type, you build a foundation for secure and compliant operations.
How to choose the right unstructured data discovery tool
If you’re evaluating tools, here are a few good questions to ask:
- Can it scan all major unstructured data repositories (including file shares)?
- Does it support classifying sensitive data within unstructured environments?
- Does it integrate with your data governance ecosystem (e.g., Collibra)?
- Does it leverage automation and advanced data techniques like machine learning?
- Can it scale as your organization grows?
This is exactly why the Collibra + Ohalo Data X-Ray combination is so powerful. It covers both discovery and governance.
The future of unstructured data discovery
This is where things get really interesting.
Despite the ongoing digital transformation, we’re not getting rid of unstructured data (well, not just yet). In fact, organizations keep generating new data at record speed. Hybrid and multi-cloud environments continue expanding. AI initiatives require clean, well-governed datasets. Regulations are tightening. Security teams are under pressure to identify risks sooner.
All of this means one thing:
The future of unstructured data discovery is continuous, intelligent, and deeply integrated into the enterprise ecosystem.
Here’s what that looks like:
1. Continuous scanning becomes the norm
Instead of one-off data discovery projects, organizations need to maintain always-on discovery pipelines that automatically detect:
- New files
- Newly added sensitive information
- Changes in access permissions
- Data that should be archived or deleted
2. AI-driven classification gets dramatically smarter
Machine learning models will move beyond pattern recognition and begin understanding:
- Context
- Intent
- Business meaning
- Risk levels
This enables more accurate classification, especially for documents that don’t follow predictable formats.
3. Data governance automation expands
Expect tighter integrations between data discovery tools and data governance platforms.
Metadata exchange will become:
- Faster
- More granular
- More automated
This means fewer manual steps, fewer blind spots, and better compliance outcomes.
4. Security posture management includes unstructured data
Today, many teams have strong visibility into structured systems, but not files. This gap will close quickly as data security posture management evolves to include:
- File repositories
- Collaboration platforms
- Messaging systems
- AI-generated documents
5. AI governance relies on high-quality discovered data
Large AI models have to be trained on clean, compliant datasets. Unstructured data discovery ensures:
- Sensitive information isn’t ingested
- Training data is accurate
- Bias and noise are reduced
- Compliance is maintained
6. The goal shifts from control to value extraction
Once unstructured data is:
- Discovered
- Classified
- Governed
…you can use it for analytics, automation, and AI. And this is where organizations unlock the true potential of their data.
Struggling with unstructured data discovery in your organization?
Talk to Murdio experts, and let’s create and implement a plan of ongoing unstructured data discovery and management using Collibra and Ohalo.
FAQs about unstructured data discovery
Ohalo Data X-Ray scans and classifies unstructured data using machine learning. Collibra then organizes the results into a governed, searchable data catalog and automates data governance workflows.
It’s scattered across repositories, lacks a consistent format, and grows faster than anyone can manually review. Many files also contain hidden sensitive content.
Banking, insurance, healthcare, and the public sector – primarily due to high regulatory requirements and sensitive data volumes.
Not anymore. Modern discovery is continuous, automated, and embedded into the organization’s data governance lifecycle.



