
On September 23, 1999, a team of world-class engineers at NASA’s Jet Propulsion Laboratory held their breath. Hundreds of millions of miles away, the Mars Climate Orbiter, a robotic space probe worth $125 million, was about to enter orbit around the Red Planet. After a journey of 286 days, years of work by hundreds of brilliant minds were about to pay off. The team waited for the signal confirming the maneuver was a success.
That signal never came.
In the ghostly silence of the control room, a mission turned into a mystery. The orbiter had vanished. An investigation was launched immediately, and what it uncovered was not a catastrophic explosion or a complex hardware malfunction, but a simple, almost absurdly small error – a foundational mistake in its data.
The problem was a failure of translation. The software built by one engineering team at Lockheed Martin calculated thruster force using English units (pound-seconds). The ground-based software at NASA, which took that data and calculated the trajectory, expected those numbers to be in metric units (newton-seconds). No one built a conversion step into the software.
Every single course correction sent to the spacecraft during its nine-month journey was off by a factor of 4.45. The errors were tiny individually, but they accumulated relentlessly over 416 million miles. The orbiter didn’t miss Mars, but it approached it at a fatally low altitude. Instead of entering a stable orbit, the probe entered the upper atmosphere and disintegrated into dust and fire.
This is the ultimate, high-stakes lesson in why data quality is not just a business buzzword or a technical chore. It’s the bedrock of every decision we make based on information.
When we truly rely on data – whether to launch a spacecraft, diagnose a patient, or forecast a company’s revenue – the quality of that data can be the difference between spectacular success and mission failure.
What is data quality (and what it isn’t)?
The NASA story is a dramatic example of how a single flaw can lead to catastrophic failure, a direct result of poor data quality. But in business, data quality issues are often more subtle. They don’t announce themselves with a fiery explosion, but silently corrupt reports, mislead marketing efforts, and erode customer trust over time.
To prevent this, the first step is to understand what we truly mean when we talk about data quality. It’s more than just “good” or “bad” information; it’s a measurable and manageable discipline.
Data quality vs. data integrity: understanding the nuances
People often use the terms data quality and data integrity interchangeably, but they represent two distinct and vital concepts.
Data Quality describes the state or characteristics of data relative to its intended purpose. It asks, “Is this data fit to be used?” Achieving high-quality data means focusing on its attributes at the point of creation – whether from a primary data source or manual data entry – and throughout its lifecycle. It’s about ensuring the information itself is reliable.
Data Integrity, on the other hand, refers to the validity and structural soundness of data throughout its lifecycle. It asks, “Has this data remained whole and unaltered?” It’s a process-focused concept, designed to ensure that the data is not accidentally or maliciously changed during storage, transfers, or processing. It protects the container.
Think of it like banking:
- Data Quality is making sure your starting account balance is recorded as $100.50, not $10050. This is a matter of data accuracy.
- Data Integrity is ensuring that when you transfer $20, the system’s process prevents that transaction from being duplicated or corrupted, so your final balance is a perfect $80.50.
You need both, but they address different challenges in the pursuit of trustworthy, effective data.
The core dimensions of data quality
To measure and talk about the quality of data, we use a set of standard criteria known as the data quality dimensions. These provide a framework for a data quality assessment and help pinpoint the source of problems, such as inconsistent data.
While there are many facets to good data quality, most experts agree on six core dimensions:
- Accuracy: Is the data correct?
- Completeness: Is all the necessary data present?
- Consistency: Does the data tell the same story across different systems?
- Timeliness: Is the data up-to-date enough for its purpose?
- Uniqueness: Is it free of duplicate data?
- Validity: Does the data conform to the required format and business rules?
These six pillars are the starting point for any data quality framework. We explore them – and two additional, advanced dimensions – in our comprehensive guide: [Link to a separate, in-depth article on the 8 Dimensions of Data Quality].
Why is data quality important?
Understanding the dimensions of data quality is one thing; understanding their impact on your bottom line is another.
The reason data quality is important is that every single modern business initiative – from personalized marketing and business intelligence to AI and machine learning – is built upon a foundation of data. If that foundation is cracked, everything you build on top of it is at risk.
The consequences of ignoring the health of your enterprise data aren’t just theoretical; they are tangible, measurable, and they ripple across your entire organization.
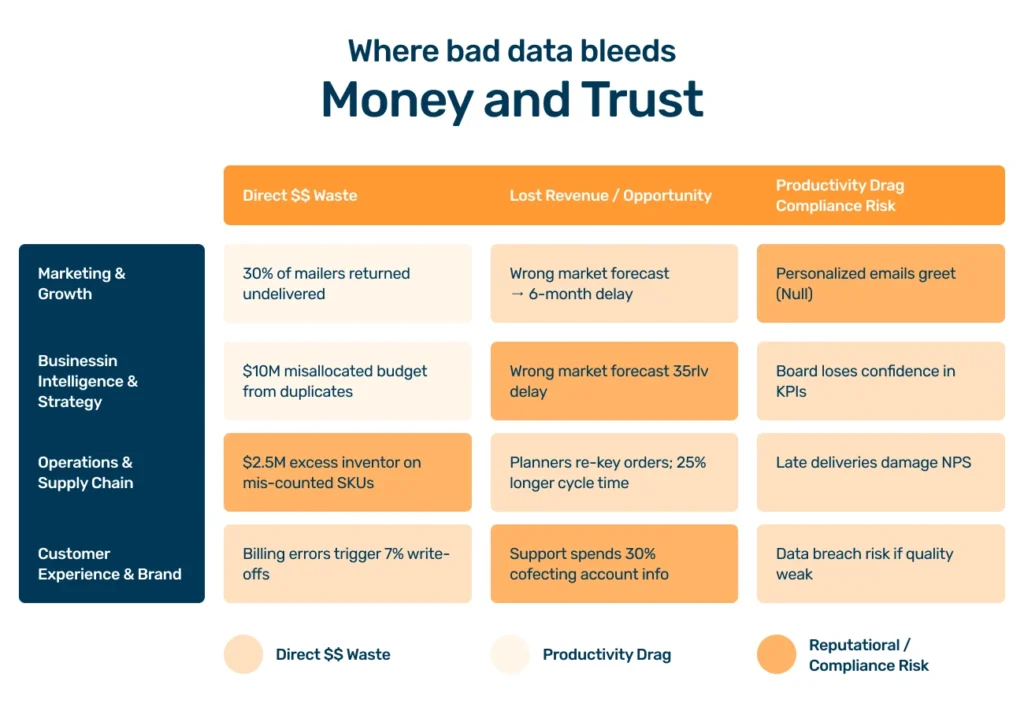
The hidden costs of poor data quality issues
One of the best ways to understand the financial impact of bad data is the “1-10-100 Rule.”
Link to png: what_is_data_quality_heatmap.png
- It costs $1 to verify a record and fix an error at the point of data entry.
- It costs $10 to find and cleanse that same record later on.
- It costs $100 (or more) if you do nothing and make decisions based on that flawed data.
These costs manifest in ways that are often hidden in plain sight.
| Area of impact | Example of hidden costs |
| Wasted resources | Marketing departments spend fortunes on campaigns targeting flawed customer data, with mailers returning to sender and emails bouncing, directly impacting budget and ROI. |
| Flawed insights | Strategic decisions are made based on BI dashboards skewed by duplicate data or inconsistent data, leading the company to invest in the wrong products or markets. |
| Operational inefficiency | Supply chains grind to a halt because of poor data accuracy in inventory systems, leading to stockouts that frustrate customers or overstocking that ties up capital. |
| Reputational damage | Nothing erodes customer trust faster than repeated billing errors or addressing them by the wrong name, leading to churn and negative word-of-mouth. |
These are just a few examples of common data quality issues. Learn more about identifying and preventing these costly pitfalls in our detailed article on [Link to article on ‘Common Data Quality Issues’].
The tangible roi of a robust data management strategy
The good news is that the flip side is also true. Investing in a proactive data management strategy to achieve and maintain data quality yields significant and measurable returns. When you address data problems head-on, you don’t just avoid costs – you create value.
Consider these “Hall of Fame” examples of high-quality data in action:
Enhanced personalization and revenue growth
A global e-commerce leader increased its revenue by over 15% by using clean, accurate, and complete customer profiles to power its recommendation engine. This made every interaction more relevant and directly led to increased customer lifetime value.
Streamlined operations and cost savings
A logistics company saved millions in fuel and shipping costs by improving the data accuracy of its routing and scheduling systems. This ensured its fleet was always on the most efficient path, reducing waste and improving delivery times.
Strengthened compliance and customer trust
A financial institution avoided hefty regulatory fines and built stronger customer trust by implementing rigorous quality standards for its enterprise data. This ensured it could pass any audit with confidence and protect its customers’ sensitive information.
Ultimately, achieving good data quality makes every other data-dependent part of your business better. It turns your information into effective data – an asset that powers growth, innovation, and a genuine competitive advantage. When you can rely on data, you can lead with confidence.
A guide to data quality management in the real world
Now that we understand what data quality is and why it’s a critical business priority, it’s time to move from theory to practice. How do successful organizations systematically improve data quality and maintain it over time?
The answer lies in a disciplined approach to data quality management. This isn’t a one-off project but an ongoing program that combines strategy, processes, and the right technology to address data quality issues proactively.
From reactive to proactive: the evolution of data quality management
For years, many organizations practiced “archaeological” data quality. They would wait until a business user’s report was disastrously wrong, then dig through layers of data to find the source of the problem. This reactive approach – fixing errors long after they’ve occurred – is expensive, inefficient, and always keeps you one step behind.
The modern approach is proactive. It’s about building quality checks into the entire data lifecycle. This means managing data quality from the moment it enters your ecosystem, whether from a primary data source or an internal application.
The goal is to catch and resolve issues automatically before they ever reach a business intelligence dashboard or a customer-facing application.
Choosing the right data quality management tools
There is no single magic button to fix all data problems. An effective strategy typically involves a stack of specialized data quality management tools, each serving a distinct purpose.
Data Profiling Tools
This is your starting point. Before you can fix your data, you need to understand it. Data profiling tools scan your databases, data lake, or other systems to create a statistical summary.
They help you answer critical questions: Are there null values in this column? What are the most common formats for dates? How many unique values exist?
This discovery phase is essential for diagnosing your specific data quality issues.
Data cleansing tools
Once you’ve identified problems through profiling, data cleansing tools help you fix them. These data quality solutions are designed to correct, standardize, enrich, and remove incorrect or improperly formatted data.
They are the workhorses that can transform inconsistent data into a standardized, reliable asset.
Data Monitoring & Observability Platforms
This is the cutting edge of data quality management. Unlike profiling, which takes a snapshot in time, these platforms continuously watch your data pipelines.
They are crucial for managing data in systems that rely on real-time data. By learning your data’s normal patterns, they can instantly alert you to anomalies – like a sudden drop in record volume or a change in a data field’s distribution – helping you catch issues in minutes, not months.
The power of machine learning in your data strategy
While traditional tools rely on user-defined rules (e.g., “flag any zip code that is not 5 digits”), machine learning takes data quality management to the next level.
By applying algorithms to your datasets, machine learning provides advanced capabilities that are impossible to achieve with manual rules alone.
| ML advantage | How it improves data quality |
| Discover complex issues | Identifies subtle patterns and correlations that signify poor data quality, which would be nearly impossible for a human to write a rule for. |
| Adapt to evolving data | As your data evolves, models can adapt and learn the new “normal,” identifying new types of errors without needing manual reconfiguration. |
| Automate at scale | Automates the identification of a wide range of issues, from sophisticated duplicate data detection to flagging outlier values, allowing you to ensure data quality across massive volumes of information. |
Integrating machine learning into your data management system is a key step toward achieving and maintaining sustainable, high data quality.
The human side of effective data management: people, processes, and governance
Even the most powerful data quality tool or advanced machine learning model will ultimately fail if the organization’s culture isn’t ready for it.
Technology is a critical enabler, but sustainable success in managing data comes from the human element: the frameworks, roles, and shared commitment that transform data management from a technical task into a business-wide discipline.
This is where you build the foundation to maintain data quality for the long term.
Data governance: the foundation of a strong data culture
If data quality is the “what,” then data governance is the “who” and “how.” It is the formal orchestration of people, processes, and technology that enables an organization to leverage its enterprise data as a true asset. It’s a system designed to answer critical questions:
- Who has ownership of this data source?
- What are the official quality standards for our customer data?
- Who has the authority to change or address data?
- How do we ensure that the data is used securely and ethically?
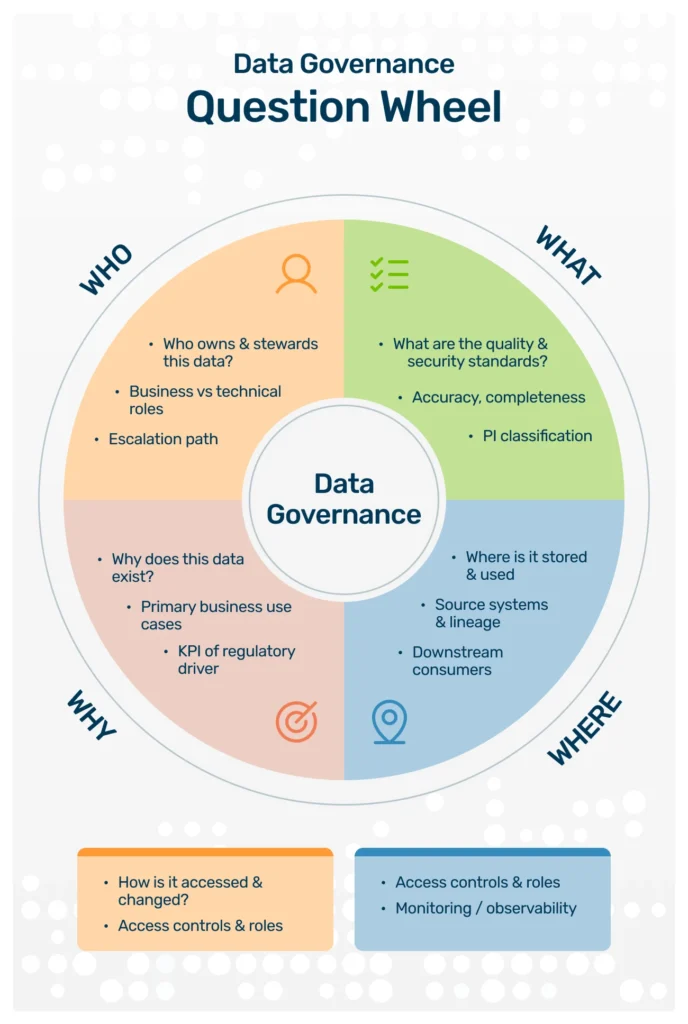
A strong data governance program creates clear accountability and consistent rules of the road, preventing the silos and miscommunication that so often lead to poor data quality.
A key part of governance is measurement. You can’t improve what you don’t measure. Get started by reading our guides on conducting a comprehensive [Link to article on ‘Data Quality Assessment’] and defining the right [Link to article on ‘Data Quality Metrics’] for your business.
Building your enterprise data quality framework
Your data quality framework is the practical blueprint that brings your governance strategy to life. It’s the “how-to” guide for your entire organization, detailing the specific activities required to achieve and maintain high-quality data.
This framework typically includes defining clear roles like data stewards, establishing official policies and quality standards for different data types, setting up workflows to resolve data quality issues, and selecting the technology to support these efforts.
This isn’t a static document you create once and file away. It’s a living part of your data management strategy that adapts as your business and data landscape evolve.
From strategy to action with collibra and murdio
Designing and implementing a robust data governance and quality framework, especially across complex enterprise data systems, is a significant undertaking. This is where a powerful platform like Collibra becomes essential, providing a central place for your entire organization to catalog, understand, and trust your data.
At Murdio, we specialize in implementing Collibra data governance solutions, helping you bridge the gap between strategy and execution. We provide the expertise to configure the platform, establish your framework, and empower your teams to build a culture of data trust. If you’re ready to take control of your enterprise data and turn your vision for effective data into a reality, [Link to Murdio’s contact or consultation page: ‘Let’s talk about how we can accelerate your data quality journey.’]
Your action plan: how to improve data quality starting today
Understanding the theory, the costs, and the need for governance is crucial, but it can also feel overwhelming. The most important thing to remember is that you don’t have to boil the ocean. The journey to high-quality data begins with a single, deliberate step.
This section provides a practical starting point, breaking down how you can begin to improve data quality within your organization right now.
A practical guide to data quality best practices
Before you dive into complex tools or large-scale projects, embed these four foundational best practices into your thinking.
1. Start with profiling, not cleansing
It’s tempting to jump straight into data cleansing, but you can’t effectively fix what you don’t understand.
The essential first step is always data profiling. Pick one critical data source – like your main customer data table – and use tools to analyze its current state.
This diagnostic phase will reveal the specific types of data quality issues you face, allowing you to focus your efforts where they’ll have the most impact.
2. Prioritize and focus
Don’t try to fix all your enterprise data at once. Identify a single, high-value business process that is suffering from poor data quality (e.g., the lead-to-cash process, marketing campaign generation, or inventory management).
By focusing your initial efforts here, you can deliver a clear, measurable win that helps build momentum and makes it easier to get buy-in for a broader data quality framework.
3. Treat data quality as a process, not a project
A one-time cleanup project will only provide temporary relief; the problems will inevitably creep back in.
To achieve sustainable improvement, you must treat data quality management as an ongoing process.
This means embedding automated checks, validation rules, and monitoring into your daily data operations to address data issues as they arise.
4. Assign clear ownership
Data quality is everyone’s responsibility, but without clear accountability, it becomes no one’s. As established in your data governance strategy, every critical data set needs a designated owner or steward. This person is the go-to contact responsible for defining its quality standards and ensuring it remains fit for purpose.
Managing data across the organization
Effectively managing data means different things depending on your role. Here’s how different teams can contribute:
For the data engineer: guarding the gates
Your primary role is to prevent bad data from entering and propagating through your systems in the first place.
- Automate validation checks directly in your data ingestion and ETL/ELT pipelines to catch format and integrity errors at the source.
- Implement schema validation to protect against unexpected structural changes that can break downstream processes.
- Set up automated alerts that trigger when real-time data volumes or statistical distributions deviate significantly from the norm.
For the business analyst: defending the last mile
You are the final bridge between data and decision-making. Your role is to ensure the insights delivered to the business are trustworthy.
- Work with business stakeholders to formally define the quality standards required for the data powering critical business intelligence reports and dashboards.
- Champion the creation of “certified” datasets that are blessed as the single source of truth for analysis, reducing confusion and conflicting reports.
- When you find a data issue, don’t just scrub it in a spreadsheet for a one-off report. Use a formal process to report the issue back to the data owner so it can be fixed permanently at the source.
This action plan is your starting point. For a complete, step-by-step methodology, read our comprehensive guide on [Link to article on ‘A 5-Step Data Quality Improvement Plan’].
Future-forward: the next frontiers of data quality
While the core principles of accuracy, completeness, and consistency are timeless, the technological landscape is in constant motion. A truly effective data strategy must not only address the challenges of today but also anticipate the frontiers of tomorrow.
The discipline of data quality management is evolving rapidly to meet the demands of new technologies and more complex data ecosystems. Here’s a look at what’s next.
Data quality in the age of big data, web3, and the metaverse
The definition of “data” itself is expanding, bringing new challenges and requiring new approaches to quality.
Big data and real-time streams
The challenge of big data isn’t just its size, but its speed. With massive volumes of real-time data flowing from IoT devices, clickstreams, and social media, annual or quarterly data cleansing is obsolete. This environment demands fully automated, machine-learning-driven observability to detect anomalies and ensure quality in motion.
Web3 and blockchain
Blockchain technology offers unprecedented data integrity, as its distributed and immutable nature prevents data from being altered after it’s recorded. However, it creates a new, high-stakes quality challenge: if bad data or an incorrect transaction is written to the chain, it’s permanently and transparently wrong. This elevates the importance of “right-at-the-source” data validation to an entirely new level.
The metaverse
As virtual worlds develop, they will generate an explosion of new, largely unstructured data types: avatar movements, spatial interactions, real-time verbal commands, and digital asset transactions. Ensuring the quality and consistency of this complex, multi-dimensional data will be a core challenge for the next generation of managing data.
Gamification: making data quality fun and engaging
One of the biggest hurdles in any data governance program is employee engagement. Gamification offers an innovative solution by applying game-design principles to the work of maintaining data quality. Imagine a system where:
- Data stewards earn points and badges for resolving data quality issues.
- A company-wide leaderboard showcases teams with the highest data accuracy scores for their domains.
- Employees are rewarded for identifying a previously unknown data source or suggesting a new quality rule.
By making data stewardship competitive and rewarding, gamification can transform a perceived chore into a collaborative and engaging cultural activity.
The future of master data management
For years, master data management (MDM) has focused on creating a single, trusted source of truth for core entities like “customer” and “product.” The future of MDM is far more ambitious.
Modern MDM is expanding to become a multi-domain hub, managing the complex, interconnected relationships between dozens of data types – people, places, assets, suppliers, and more.
Powered by AI and graph database technologies, next-generation MDM will not just store master records but will actively discover relationships and provide rich, contextualized, and high-quality data that serves as the intelligent core of the entire enterprise data landscape.
Conclusion: the journey to data quality is a marathon, not a sprint
We began this journey with a mission to Mars to illustrate a fundamental truth: the quality of our data directly determines the outcome of our most critical endeavors. From that high-stakes example, we’ve explored what data quality truly is, why it’s the financial and strategic bedrock of a modern enterprise, and how a combination of technology, process, and culture is required to achieve it.
We’ve seen that modern data quality management moves beyond reactive cleanup, embracing proactive monitoring and machine learning. More importantly, we’ve established that the most powerful tools are only effective when supported by a strong foundation of data governance – a shared commitment to treating data as a primary business asset.
Ultimately, data quality is not a project with a finish line. It is a continuous discipline, a cultural mindset that must be woven into the fabric of your organization. It is the essential, non-negotiable foundation for every other data initiative you undertake, from business intelligence and master data management to the complex worlds of big data, AI, and data security.
In an era where organizations increasingly rely on data to compete and innovate, the quality of that data is no longer a simple advantage – it is the price of admission. The businesses that will lead their industries in the next decade will be those that transform their information into truly effective data.
The journey may seem long, but it starts with a single step. Start by profiling one critical data set. Have one conversation about data ownership. To help you understand where you stand today, read our [Link to ‘Data Quality Maturity Assessment’] guide to get a baseline for your own journey toward data excellence.
About the Author

Share this article
Related Articles
See all-

7 January 2026
| Collibra experts for hireData governance framework. Best practices & examples
-

6 January 2026
| Collibra experts for hireBuilding a data governance strategy
-

6 January 2026
| Collibra experts for hireData observability vs data quality: key differences